SVM model
SVM (Support Vector Machines) is a nice framework to test new ideas for various types of problems. The power of SMVs comes from their kernels. A kernel is basically a transformation of the original space generated by the input features into another space, often with more dimensions. It's like a feature engineering in a singe function.
But SVMs have a practical problem. The features needs to be numeric and does not allows missing values. This is not a constrain on the algorithm itself. At any moment one can build a kernel for nominal features. But the implemented ones allows only numeric non missing values and is much simpler to shape our data into this format.
How can we do that?
Data preparation
We can use a filter to impute data for missing values. The filter we use is an imputation with a classifier of imputation with a regression. The logic is the following: train a classifier from a specified set of input features to predict the field with missing values. The data set inside the filter is filtered to contain only instances with non-missing target values.
After we impute the missing values we encode nominal features into numeric features. We can accomplish this task using, again, another filter for this purpose. The name of this filter is FFOneHotEncoding. What it does is to create a number of numeric feature for level of the nominal variable. Than the values on these numeric variables receives the value of the indicator function. We have if the level equals the numeric variable's name, otherwise.
After we have numerical variables, is better to make all the variables to be in the same range. This is not a requirement for SMVs in general. The meaning is to give same weight to all the involved variables. As a side effect it makes the algorithm to run faster. This is due to the fact that the convex optimization problem has smaller chances to have a close-to-flat big surfaces.
Finally, we will remove the not used variables from the frame in order to be prepared for learning.
FFilter[] inputFilters = new FFilter[]{
new CustomFilter(),
new FFImputeWithRegression(RForest.newRF().withRuns(100),
new VarRange("Age,Pclass,Embarked,Sex,Fare,Title"), "Age"),
new FFImputeByClassifier(CForest.newRF().withRuns(10),
new VarRange("Embarked,Age,Pclass,Sex,Title"), "Embarked"),
new FFImputeByClassifier(CForest.newRF().withRuns(100),
new VarRange("Age,Pclass,Embarked,Sex,Fare,Ticket"), "Ticket"),
new FFImputeByClassifier(CForest.newRF().withRuns(100),
new VarRange("Age,Pclass,Embarked,Sex,Fare,Cabin"), "Cabin"),
new FFOneHotEncoding("Sex,Embarked,Title,Cabin"),
new FFOneHotEncoding("Ticket"),
new FFStandardize("all"),
new FFRemoveVars("PassengerId,Name,SibSp,Parch")
};
train.applyFilters(inputFilters).printSummary()
Frame Summary
=============
* rowCount: 891
* complete: 891/891
* varCount: 41
* varNames:
0. Survived : nom | 14. Ticket.3 : num | 28. Cabin.G : num |
1. Pclass : num | 15. Ticket.2 : num | 29. Cabin.D : num |
2. Sex.male : num | 16. Ticket.C : num | 30. Cabin.A : num |
3. Sex.female : num | 17. Ticket.7 : num | 31. Cabin.B : num |
4. Age : num | 18. Ticket.W : num | 32. Cabin.F : num |
5. Fare : num | 19. Ticket.4 : num | 33. Cabin.T : num |
6. Embarked.S : num | 20. Ticket.F : num | 34. Title.Master : num |
7. Embarked.C : num | 21. Ticket.L : num | 35. Title.Rev : num |
8. Embarked.Q : num | 22. Ticket.9 : num | 36. Title.Mr : num |
9. FamilySize : num | 23. Ticket.6 : num | 37. Title.Miss : num |
10. Ticket.A : num | 24. Ticket.5 : num | 38. Title.Dr : num |
11. Ticket.P : num | 25. Ticket.8 : num | 39. Title.Mrs : num |
12. Ticket.S : num | 26. Cabin.C : num | 40. Title.Military : num |
13. Ticket.1 : num | 27. Cabin.E : num |
Survived Pclass Sex.male Sex.female Age
0 : 549 Min. : -1.565 Min. : -1.355 Min. : -0.737 Min. : -2.781
1 : 342 1st Qu. : -0.369 1st Qu. : -1.355 1st Qu. : -0.737 1st Qu. : -0.336
Median : 0.827 Median : 0.737 Median : -0.737 Median : -0.113
Mean : -0.000 Mean : -0.000 Mean : 0.000 Mean : 0.000
2nd Qu. : 0.827 2nd Qu. : 0.737 2nd Qu. : 1.355 2nd Qu. : 0.483
Max. : 0.827 Max. : 0.737 Max. : 1.355 Max. : 2.929
Fare Embarked.S Embarked.C Embarked.Q FamilySize
Min. : -0.648 Min. : -1.632 Min. : -0.482 Min. : -0.303 Min. : -0.561
1st Qu. : -0.489 1st Qu. : -1.632 1st Qu. : -0.482 1st Qu. : -0.303 1st Qu. : -0.561
Median : -0.357 Median : 0.612 Median : -0.482 Median : -0.303 Median : -0.561
Mean : 0.000 Mean : 0.000 Mean : 0.000 Mean : 0.000 Mean : -0.000
2nd Qu. : -0.024 2nd Qu. : 0.612 2nd Qu. : -0.482 2nd Qu. : -0.303 2nd Qu. : 0.059
Max. : 9.662 Max. : 0.612 Max. : 2.073 Max. : 3.297 Max. : 5.637
Ticket.A Ticket.P Ticket.S Ticket.1 Ticket.3
Min. : -0.139 Min. : -0.280 Min. : -0.251 Min. : -0.433 Min. : -0.767
1st Qu. : -0.139 1st Qu. : -0.280 1st Qu. : -0.251 1st Qu. : -0.433 1st Qu. : -0.767
Median : -0.139 Median : -0.280 Median : -0.251 Median : -0.433 Median : -0.767
Mean : -0.000 Mean : -0.000 Mean : -0.000 Mean : -0.000 Mean : 0.000
2nd Qu. : -0.139 2nd Qu. : -0.280 2nd Qu. : -0.251 2nd Qu. : -0.433 2nd Qu. : 1.303
Max. : 7.166 Max. : 3.563 Max. : 3.974 Max. : 2.305 Max. : 1.303
Ticket.2 Ticket.C Ticket.7 Ticket.W Ticket.4
Min. : -0.508 Min. : -0.261 Min. : -0.101 Min. : -0.101 Min. : -0.106
1st Qu. : -0.508 1st Qu. : -0.261 1st Qu. : -0.101 1st Qu. : -0.101 1st Qu. : -0.106
Median : -0.508 Median : -0.261 Median : -0.101 Median : -0.101 Median : -0.106
Mean : 0.000 Mean : -0.000 Mean : -0.000 Mean : 0.000 Mean : 0.000
2nd Qu. : -0.508 2nd Qu. : -0.261 2nd Qu. : -0.101 2nd Qu. : -0.101 2nd Qu. : -0.106
Max. : 1.966 Max. : 3.823 Max. : 9.894 Max. : 9.894 Max. : 9.381
Ticket.F Ticket.L Ticket.9 Ticket.6 Ticket.5
Min. : -0.082 Min. : -0.067 Min. : 0.000 Min. : -0.067 Min. : -0.034
1st Qu. : -0.082 1st Qu. : -0.067 1st Qu. : 0.000 1st Qu. : -0.067 1st Qu. : -0.034
Median : -0.082 Median : -0.067 Median : 0.000 Median : -0.067 Median : -0.034
Mean : -0.000 Mean : -0.000 Mean : 0.000 Mean : -0.000 Mean : -0.000
2nd Qu. : -0.082 2nd Qu. : -0.067 2nd Qu. : 0.000 2nd Qu. : -0.067 2nd Qu. : -0.034
Max. : 12.138 Max. : 14.883 Max. : 0.000 Max. : 14.883 Max. : 29.816
Ticket.8 Cabin.C Cabin.E Cabin.G Cabin.D
Min. : -0.047 Min. : -0.379 Min. : -0.615 Min. : -0.301 Min. : -0.499
1st Qu. : -0.047 1st Qu. : -0.379 1st Qu. : -0.615 1st Qu. : -0.301 1st Qu. : -0.499
Median : -0.047 Median : -0.379 Median : -0.615 Median : -0.301 Median : -0.499
Mean : -0.000 Mean : -0.000 Mean : 0.000 Mean : -0.000 Mean : 0.000
2nd Qu. : -0.047 2nd Qu. : -0.379 2nd Qu. : 1.623 2nd Qu. : -0.301 2nd Qu. : -0.499
Max. : 21.071 Max. : 2.636 Max. : 1.623 Max. : 3.321 Max. : 2.000
Cabin.A Cabin.B Cabin.F Cabin.T Title.Master
Min. : -0.159 Min. : -0.269 Min. : -0.538 Min. : 0.000 Min. : -0.217
1st Qu. : -0.159 1st Qu. : -0.269 1st Qu. : -0.538 1st Qu. : 0.000 1st Qu. : -0.217
Median : -0.159 Median : -0.269 Median : -0.538 Median : 0.000 Median : -0.217
Mean : 0.000 Mean : -0.000 Mean : 0.000 Mean : 0.000 Mean : 0.000
2nd Qu. : -0.159 2nd Qu. : -0.269 2nd Qu. : -0.538 2nd Qu. : 0.000 2nd Qu. : -0.217
Max. : 6.281 Max. : 3.719 Max. : 1.858 Max. : 0.000 Max. : 4.610
Title.Rev Title.Mr Title.Miss Title.Dr Title.Mrs
Min. : -0.082 Min. : -1.183 Min. : -0.510 Min. : -0.089 Min. : -0.409
1st Qu. : -0.082 1st Qu. : -1.183 1st Qu. : -0.510 1st Qu. : -0.089 1st Qu. : -0.409
Median : -0.082 Median : 0.844 Median : -0.510 Median : -0.089 Median : -0.409
Mean : -0.000 Mean : -0.000 Mean : -0.000 Mean : 0.000 Mean : -0.000
2nd Qu. : -0.082 2nd Qu. : 0.844 2nd Qu. : -0.510 2nd Qu. : -0.089 2nd Qu. : -0.409
Max. : 12.138 Max. : 0.844 Max. : 1.959 Max. : 11.231 Max. : 2.440
Title.Military
Min. : -0.082
1st Qu. : -0.082
Median : -0.082
Mean : 0.000
2nd Qu. : -0.082
Max. : 12.138
There is a lot of content. Notice that we have numerical variables for each ticket first letter, title, cabin first letter, etc.
Train a polynomial SVM
A linear kernel is a polynomial kernel with degree 1. We let the parameter to the default value which is .
Classifier model = new BinarySMO()
.withInputFilters(inputFilters)
.withC(0.0001)
.withKernel(new PolyKernel(1));
model.train(train, "Survived");
CFit fit = model.fit(test);
new Confusion(train.var("Survived"), model.fit(train).firstClasses()).printSummary();
new Csv().withQuotes(false).write(SolidFrame.wrapOf(
test.var("PassengerId"),
fit.firstClasses().withName("Survived")
), root + "svm1-submit.csv");
cv(train, model);
> Confusion
Ac\Pr | 0 1 | total
----- | - - | -----
0 | >292 257 | 549
1 | 41 >301 | 342
----- | - - | -----
total | 333 558 | 891
Complete cases 891 from 891
Acc: 0.6655443 (Accuracy )
F1: 0.6621315 (F1 score / F-measure)
MCC: 0.4141426 (Matthew correlation coefficient)
Pre: 0.8768769 (Precision)
Rec: 0.5318761 (Recall)
G: 0.6829274 (G-measure)
Cross validation 10-fold
CV fold: 1, acc: 0.666667, mean: 0.666667, se: NaN
CV fold: 2, acc: 0.764045, mean: 0.715356, se: 0.068857
CV fold: 3, acc: 0.775281, mean: 0.735331, se: 0.059730
CV fold: 4, acc: 0.707865, mean: 0.728464, se: 0.050666
CV fold: 5, acc: 0.719101, mean: 0.726592, se: 0.044077
CV fold: 6, acc: 0.696629, mean: 0.721598, se: 0.041278
CV fold: 7, acc: 0.842697, mean: 0.738898, se: 0.059286
CV fold: 8, acc: 0.730337, mean: 0.737828, se: 0.054972
CV fold: 9, acc: 0.752809, mean: 0.739492, se: 0.051663
CV fold:10, acc: 0.808989, mean: 0.746442, se: 0.053437
=================
mean: 0.746442, se: 0.053437
The results are not promising. This is better than random but it is not enough for our purpose. There are some explanations for this result. First one could be that if the space would be linear, than the original feature space would be the same as transformed. This means that a classifier as random forest would work well if the linear svm would have worked. This might not be true in general, but in this case it looks like a good explanation. We need to be more flexible.
To increase the flexibility of the model and to allow features to interact with one another we change the degree of the polynomial kernel. This time we will use degree=3. Also, we use to allow for some errors. This parameter is the factor of the slack regularization constraints of the SVM optimization problem. The bigger the value the more is the penalty for wrong decisions. If the space would be linear separable than one can theoretically set this value as high as possible. But we know it is not. Also we know that we have plenty of irreducible error. As a consequence, it looks like we should decrease the value of this parameter.
Classifier model = new BinarySMO()
.withInputFilters(inputFilters)
.withC(0.0001)
.withKernel(new PolyKernel(1));
model.train(train, "Survived");
CFit fit = model.fit(test);
new Confusion(train.var("Survived"), model.fit(train).firstClasses()).printSummary();
new Csv().withQuotes(false).write(SolidFrame.wrapOf(
test.var("PassengerId"),
fit.firstClasses().withName("Survived")
), root + "svm1-submit.csv");
cv(train, model);
> Confusion
Ac\Pr | 0 1 | total
----- | - - | -----
0 | >472 77 | 549
1 | 48 >294 | 342
----- | - - | -----
total | 520 371 | 891
Complete cases 891 from 891
Acc: 0.8597082 (Accuracy )
F1: 0.8830683 (F1 score / F-measure)
MCC: 0.7097044 (Matthew correlation coefficient)
Pre: 0.9076923 (Precision)
Rec: 0.859745 (Recall)
G: 0.8833934 (G-measure)
Cross validation 10-fold
CV fold: 1, acc: 0.822222, mean: 0.822222, se: NaN
CV fold: 2, acc: 0.786517, mean: 0.804370, se: 0.025248
CV fold: 3, acc: 0.853933, mean: 0.820891, se: 0.033728
CV fold: 4, acc: 0.808989, mean: 0.817915, se: 0.028174
CV fold: 5, acc: 0.797753, mean: 0.813883, se: 0.026012
CV fold: 6, acc: 0.786517, mean: 0.809322, se: 0.025809
CV fold: 7, acc: 0.831461, mean: 0.812484, se: 0.025002
CV fold: 8, acc: 0.876404, mean: 0.820474, se: 0.032350
CV fold: 9, acc: 0.764045, mean: 0.814204, se: 0.035631
CV fold:10, acc: 0.820225, mean: 0.814806, se: 0.033647
=================
mean: 0.814806, se: 0.033647
This time the results are promising. We achieved a training error which is not close to zero and the cross validation errors are close to our desired results. We definitely should try this classifier.
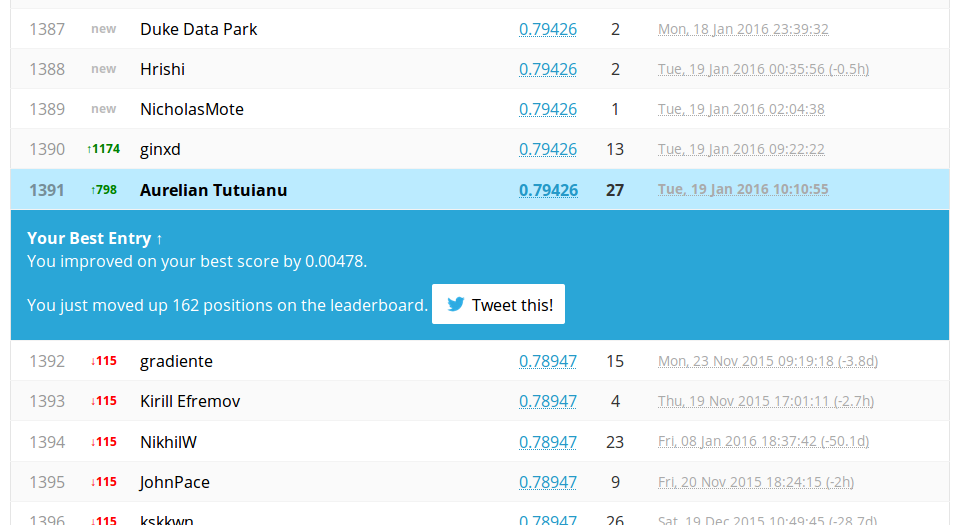
We have a better score also on public leader board. Which is very fine. Usually in this competition a score in is fine and one in is excellent.
Tuning manually the SVM
We can work more on SVMs. One thing which deserves a try is the radial basis kernel. This is similar with working in an infinite dimensional space! We tried some RBFKernel approaches, but much better results gave the CauchyKernel. The CauchyKernel works in a similar way like a RBF kernel. The difference which sometimes is important is that it is a distribution with tails fatter than Gaussian distribution. This produces an effect of long distance influence. This is reasonable to use in this problem because we know we have noise. We can think that a kernel which acts on wider ranges is better if it is combined with a small value for .
After some manual tuning we arrived at the following classifier.
Classifier model = new BinarySMO()
.withInputFilters(inputFilters)
.withC(1)
.withTol(1e-10)
.withKernel(new CauchyKernel(25));
> Confusion
Ac\Pr | 0 1 | total
----- | - - | -----
0 | >520 29 | 549
1 | 104 >238 | 342
----- | - - | -----
total | 624 267 | 891
Complete cases 891 from 891
Acc: 0.8507295 (Accuracy )
F1: 0.8866155 (F1 score / F-measure)
MCC: 0.6826819 (Matthew correlation coefficient)
Pre: 0.8333333 (Precision)
Rec: 0.9471767 (Recall)
G: 0.8884334 (G-measure)
Cross validation 10-fold
CV fold: 1, acc: 0.811111, mean: 0.811111, se: NaN
CV fold: 2, acc: 0.786517, mean: 0.798814, se: 0.017391
CV fold: 3, acc: 0.865169, mean: 0.820932, se: 0.040235
CV fold: 4, acc: 0.797753, mean: 0.815137, se: 0.034836
CV fold: 5, acc: 0.831461, mean: 0.818402, se: 0.031040
CV fold: 6, acc: 0.842697, mean: 0.822451, se: 0.029481
CV fold: 7, acc: 0.820225, mean: 0.822133, se: 0.026926
CV fold: 8, acc: 0.820225, mean: 0.821895, se: 0.024937
CV fold: 9, acc: 0.797753, mean: 0.819212, se: 0.024676
CV fold:10, acc: 0.831461, mean: 0.820437, se: 0.023585
=================
mean: 0.820437, se: 0.023585
This classifier has similar results, but there are reasons to believe that it is slightly better than previous. The training error smaller. But we know that training error is not a good estimator. The 10 fold cv is greater. This is a good sign. A better interpretation would be that the gap between those two has shrunken and this is a good thing. A new submit on kaggle follows.
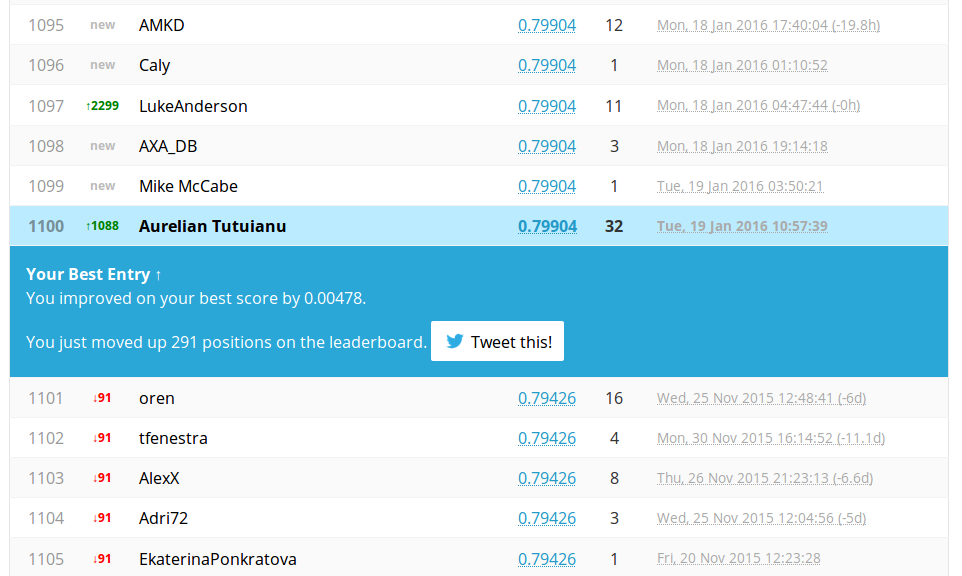
Well we are really, really close to our psychological milestone of . Perhaps some tuning will give more results. This is true in general. However, next section provides you with a better approach which usually provides some gain in accuracy: stacking.